- Published: 2023-04-12
- Categories: Review
- Tags: acrobat, bookscan, file reduce, finereader, ocr, pdf
https://youtube.com/shorts/Uxf02kkXZJI
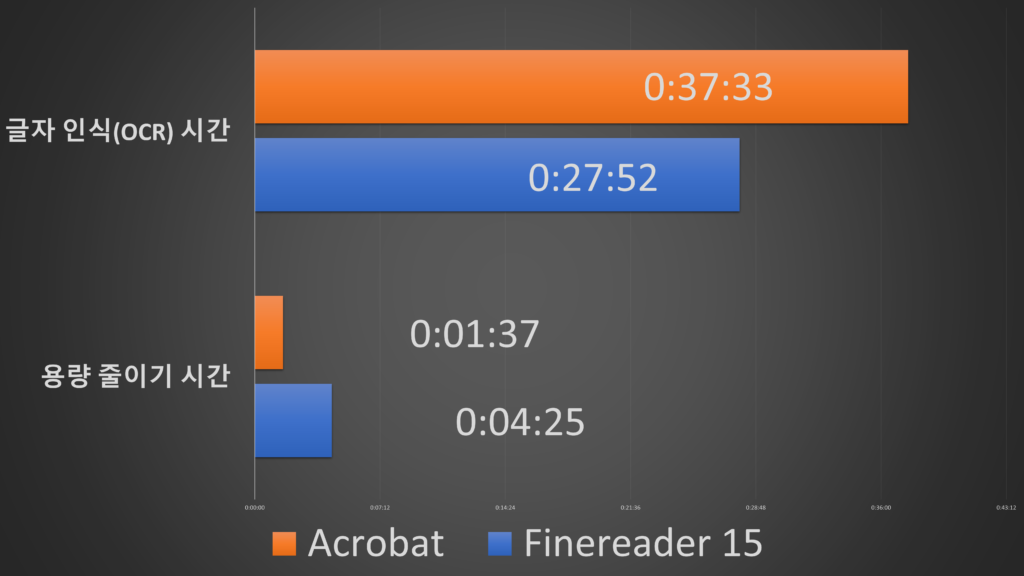
글자 인식 시간은 Abbyy Finereader가 빨랐습니다. 파일 용량 줄이기 시간은 Adobe Acrobat이 빨랐습니다. 글자 인식과 파일 용량 시간을 포함해서 비교할 경우 Abbyy Finereader가 빨랐습니다.
Adobe Acrobat 한글 인식은 윈도우에서 불가능(!???) 했습니다.
도서 스캔 후 글자인식(OCR)및 용량 줄이기
Test System : AMD 5600x, 32GB, Windows 11 and Apple M1 pro 10core, 16GB
전자책이 출간 되었으면 전자책을 구입을 하지만, 전자책이 없을 경우 종이책을 구입해서 스캔을 하고 있습니다.
저는 도서 스캔을 스캐너 최고 해상도로 스캔 한 후, 글자 인식을 하고 이후에 실제 사용은 PDF 파일 용량 줄인 파일을 사용하고 있습니다.
글자 인식 시간은 Abbyy Finereader15가빨랐고, 용량 줄이기 시간은 Adobe Acrobat이 빨랐습니다.
종합 시간으로 비교하게 되면 Abbyy Finereader15가 빠르기 때문에 계속 해서 Abbyy Finereader15를 사용할 것 같습니다.
Acrobat 한글 인식 에러 관련
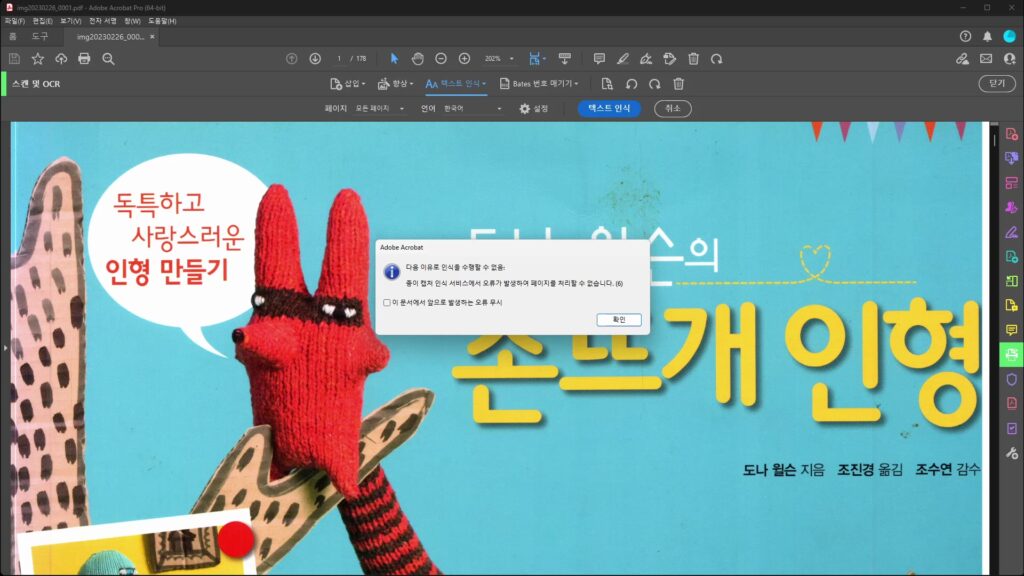
오류 메세지
다음 이유로 인식을 수행할 수 없음: 종이 캡처 인식 서비스에서 오류가 발생하여 페이지를 처리할 수 없습니다. (6)
해결 방법 (해결 안됨)
Acrobat could not access the recognition service when attempting OCR on Windows
Windows에서 OCR을 시도하려고 하면 Acrobat에서 인식 서비스에 액세스할 수 없었음
Adobe 도움말 페이지에서는 해결 방법 1과 해결 방법2 총 2가지의 방법을 제시하고 있지만, 두 가지 방법 모두 시도해봐도 한글 OCR 인식 문제는 해결되지 않았습니다.
오류 발생 시스템 목록 Desktop : AMD 5600X, 32GB, Windows 11 Notebook #1 : Intel i7-6600U,16GB, Windows 10 Notebook #2 : AMD Ryzen 9 5900HS, 16GB, Windows 11 Notebook #3 : Intel i5-7200U, 8GB, Windows 10
제가 가지고 있는 모든 윈도우 PC에서 공통적으로 같은 에러가 발생합니다.